What Makes Step3-VL-10B Revolutionary?
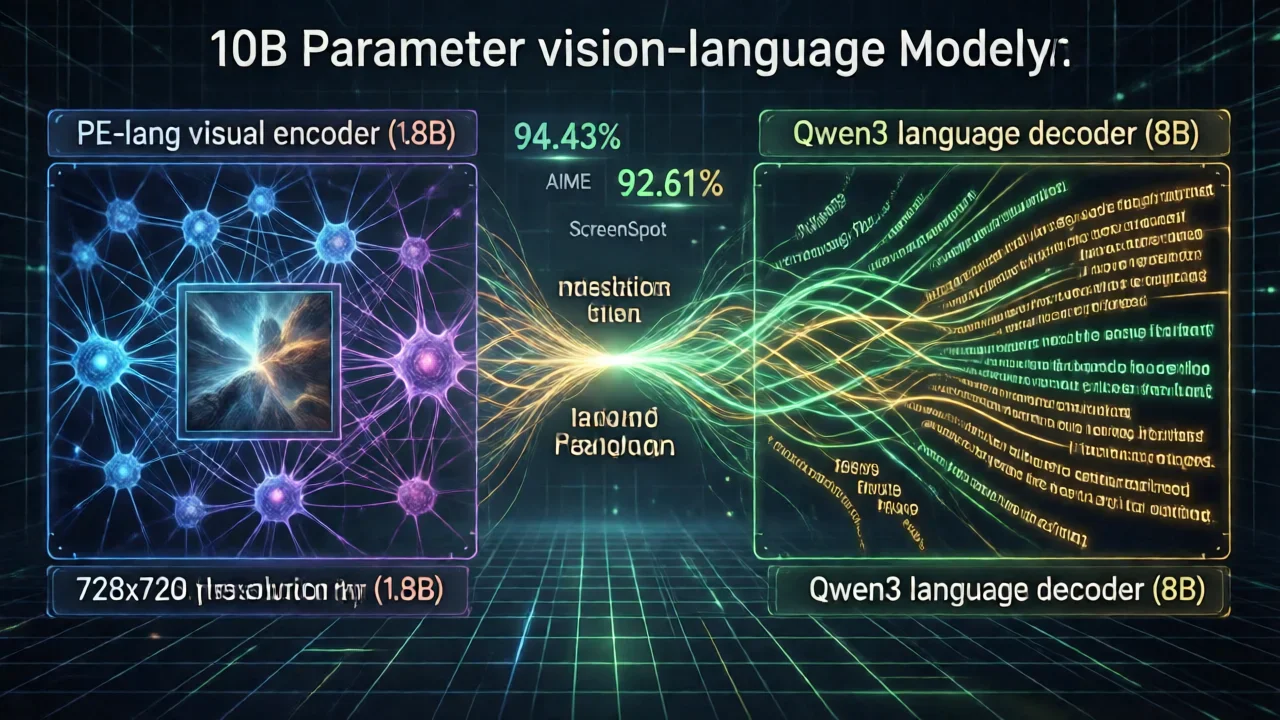
Stepfun AI just released Step3-VL-10B in January 2026. It's a 10-billion parameter vision-language model that does something unusual—it performs as well as models 10 to 20 times larger. The secret is combining a 1.8B PE-lang visual encoder with an 8B Qwen3 language decoder.
The PE-lang Advantage
The key innovation is PE-lang (Language-Optimized Perception Encoder)—a 1.8B visual encoder built specifically for language-heavy tasks. Key architectural innovations:
- Multi-crop resolution strategy: 728×728 global view combined with multiple 504×504 local crops
- 16× spatial downsampling: Efficient visual token compression
- Language-aligned tokenization: Visual tokens optimized for language models
Unified Training Pipeline
Pre-training Phase: 1.2 trillion tokens of multimodal data with single-stage, fully unfrozen training
Supervised Fine-tuning: Approximately 226 billion tokens with two-stage approach
Reinforcement Learning: Over 1,400 RL iterations combining RLVR, RLHF, and PaCoRe training
Performance Benchmarks
STEM Reasoning Excellence
| Benchmark | Step3-VL-10B | Larger Models | Advantage |
|---|---|---|---|
| AIME 2025 | 94.43% | ~85-90% | +4-9% |
| HMMT 2025 | 92.14% | ~80-85% | +7-12% |
| MathVision | 75.95% | ~65-70% | +6-11% |
| OCRBench | 89.00% | ~80-85% | +4-9% |
General Vision-Language Understanding
| Benchmark | Score | Category |
|---|---|---|
| MMMU | 78.11% | Multimodal reasoning |
| MMBench (EN) | 92.05% | General visual understanding |
| MathVista | 83.97% | Mathematical visual reasoning |
| ScreenSpot-V2 | 92.61% | GUI understanding |
Technical Specifications
| Component | Specification |
|---|---|
| Total Parameters | 10 billion |
| Visual Encoder (PE-lang) | 1.8 billion parameters |
| Language Decoder (Qwen3) | 8 billion parameters |
| Model Weights Size | 20 GB |
| Data Type | BF16 (Brain Float 16) |
| License | Apache 2.0 |
Hardware Requirements
Minimum Configuration:
- VRAM Required: 24 GB minimum
- Recommended GPUs: RTX 4090, A100, H100
- Total Memory: ~24 GB
Recommended Configuration for Production:
- VRAM: 40-80 GB (for batching and PaCoRe mode)
- GPU: A100 (80GB) or H100 (80GB)
- Storage: 30 GB (model + cache)
Core Capabilities and Use Cases
1. STEM Problem Solving
- Mathematics tutoring and problem solving
- Physics simulations and diagram analysis
- Chemistry visualization and molecular structures
- Engineering analysis and technical diagrams
2. Document Understanding and OCR
- Document digitization and conversion
- Form processing and data extraction
- Receipt and invoice analysis
- Automated data extraction
3. GUI and Screen Understanding
- UI automation and interaction
- Accessibility features for visually impaired users
- Testing automation and UI element identification
- Mobile app analysis
Deployment Options
Option 1: Hugging Face Transformers
from transformers import AutoProcessor, AutoModelForCausalLM
model_path = "stepfun-ai/Step3-VL-10B"
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True, device_map="auto", torch_dtype="auto"
).eval()Option 2: vLLM (Production API)
vllm serve stepfun-ai/Step3-VL-10B -tp 1 --trust-remote-codeOption 3: SGLang (High-Performance)
sglang serve --model-path stepfun-ai/Step3-VL-10B --trust-remote-code --port 2345Performance Optimization
1. Batch Processing
- Batch size 4-8 for 24GB VRAM
- Batch size 16-32 for 80GB VRAM
2. PaCoRe Mode Tuning
- Standard mode: 1 rollout (baseline)
- PaCoRe-4: 4 rollouts (moderate boost)
- PaCoRe-16: 16 rollouts (maximum accuracy)
3. Input Optimization
- Resize images to 728×728 or smaller
- Use JPEG compression for efficiency
- Batch similar-sized images
Comparison with Alternatives
vs. GPT-4V
Step3-VL-10B Advantages: Open-source, self-hostable, lower costs, comparable STEM performance
vs. LLaVA and Qwen-VL
Step3-VL-10B Advantages: Superior STEM reasoning, better OCR, more efficient parameters, stronger GUI understanding
Limitations
- Requires 24GB VRAM minimum
- Inference time: 5-15 seconds per image
- Training data cutoff: Early 2026
- Primarily optimized for English and Chinese
Conclusion
Step3-VL-10B represents a significant achievement in efficient vision-language model design. By combining innovative architecture (PE-lang encoder), sophisticated training strategies, and careful parameter allocation, Stepfun AI has created a model that delivers exceptional performance while remaining practical for self-hosted deployment.
Whether you're building STEM tutoring systems, document processing pipelines, or GUI automation tools, Step3-VL-10B offers a compelling combination of capability, efficiency, and accessibility.