Microsoft officially open-sourced VibeVoice-ASR on January 21, 2026, marking a significant advancement in automatic speech recognition (ASR) technology. This unified speech-to-text model is specifically designed to handle long-form audio processing, offering unprecedented capabilities for transcription, speaker diarization, and timestamping in a single pass.

What is VibeVoice-ASR?
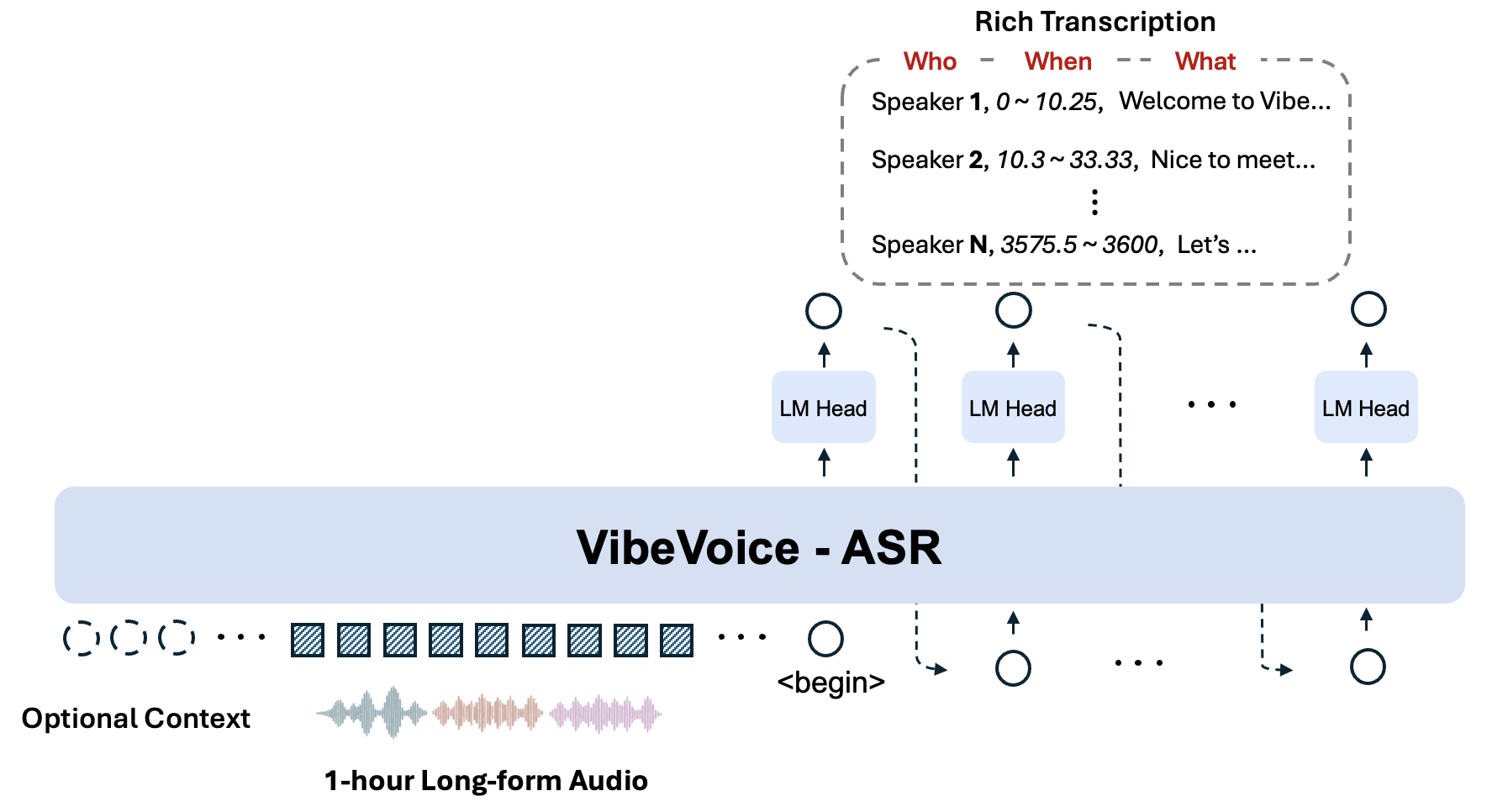
VibeVoice-ASR is a state-of-the-art speech recognition model developed by Microsoft Research. Unlike traditional ASR systems that struggle with extended audio files, VibeVoice-ASR can process up to 60 minutes of continuous audio within a single inference pass, maintaining consistent speaker tracking and semantic coherence throughout the entire recording.
The model represents a breakthrough in speech-to-text technology by combining three critical functions into one unified system:
- Automatic Speech Recognition (ASR): Converting spoken words into text
- Speaker Diarization: Identifying and tracking different speakers
- Timestamping: Providing precise temporal markers for each utterance
This integration eliminates the need for separate processing pipelines, significantly improving efficiency and accuracy for long-form audio transcription tasks.
Key Features and Capabilities
60-Minute Single-Pass Processing
One of VibeVoice-ASR's most impressive features is its ability to handle up to 60 minutes of continuous audio in a single pass. This capability is achieved through advanced architectural design that operates within a 64K token length limit while maintaining global context awareness.
Traditional ASR models typically require chunking long audio files into smaller segments, which can lead to:
- Loss of contextual information across segments
- Inconsistent speaker identification
- Fragmented transcription quality
- Increased processing complexity
VibeVoice-ASR solves these problems by processing the entire audio file at once, ensuring consistent speaker tracking and maintaining semantic coherence throughout the recording.
Structured Transcription Output (Who, When, What)
VibeVoice-ASR generates rich, structured transcriptions that answer three fundamental questions:
- Who: Speaker identification and tracking
- When: Precise timestamps for each utterance
- What: Accurate transcription of spoken content
This structured output format is particularly valuable for:
- Meeting transcription and analysis
- Interview documentation
- Podcast and video content indexing
- Legal and medical transcription
- Educational content processing
The model performs joint ASR, speaker diarization, and timestamping simultaneously, eliminating the need for post-processing steps and reducing overall transcription time.
Custom Hotword Support
VibeVoice-ASR includes a powerful hotword customization feature that allows users to provide specific terminology, names, or technical terms to improve recognition accuracy for domain-specific content. This is particularly useful for:
- Technical Documentation: Ensuring accurate transcription of specialized terminology
- Business Meetings: Correctly capturing company names, product names, and industry jargon
- Medical Transcription: Accurately recognizing medical terms and drug names
- Legal Proceedings: Properly transcribing legal terminology and case references
- Academic Content: Capturing technical terms, researcher names, and specialized vocabulary
By providing custom hotwords, users can significantly improve transcription accuracy in their specific domain without requiring model fine-tuning or retraining.
Ultra-Low Frame Rate Processing
VibeVoice-ASR operates at an ultra-low 7.5 Hz frame rate using continuous speech tokenizers. This innovative approach enables:
- Efficient processing of long-form audio
- Reduced computational requirements
- Faster inference times
- Lower memory consumption
The low frame rate doesn't compromise accuracy; instead, it allows the model to maintain a broader temporal context while processing audio more efficiently.
Technical Specifications
Model Architecture
VibeVoice-ASR is built on the Qwen2.5 architecture, leveraging advanced language model capabilities for speech understanding. The model uses a Speech-Augmented Language Model (SALM) approach that combines:
- Base Model: Qwen2.5 foundation
- Parameter Count: 9 billion parameters (some sources indicate 7B variant)
- Tensor Type: BF16 (Brain Floating Point 16-bit)
- Format: Safetensors for efficient loading and deployment
- Framework: Next-token diffusion with LLM integration
This architecture enables VibeVoice-ASR to leverage both speech-specific processing and general language understanding, resulting in superior transcription quality and contextual awareness.
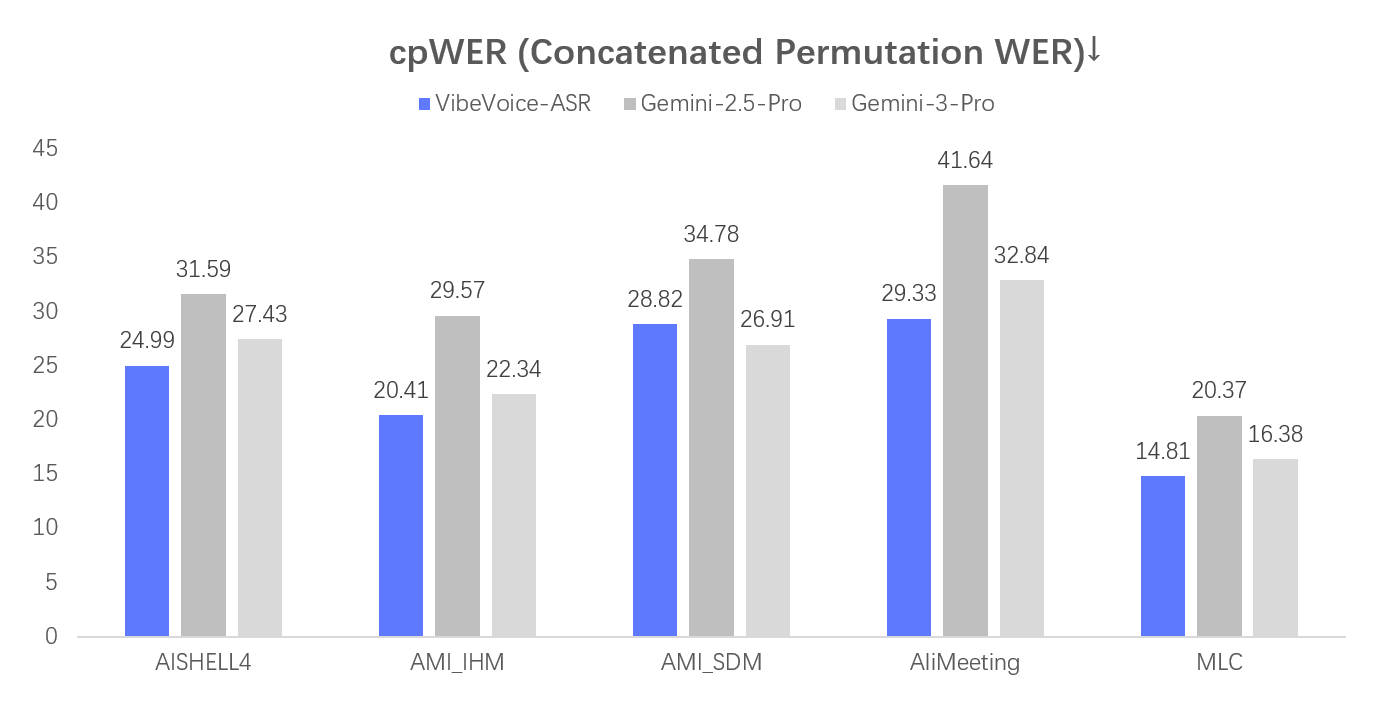
Performance Metrics
VibeVoice-ASR is evaluated using three key metrics:
- DER (Diarization Error Rate): Measures the accuracy of speaker identification and segmentation
- cpWER (Character-level Phoneme Word Error Rate): Evaluates transcription accuracy at the character level
- tcpWER (Time-Constrained Phoneme WER): Assesses both transcription accuracy and temporal alignment
According to benchmark results, VibeVoice-ASR demonstrates competitive performance across all three metrics, making it suitable for production use cases requiring high accuracy.
Hardware Requirements
Running VibeVoice-ASR requires substantial computational resources due to its 9 billion parameter size:
Minimum Requirements:
- GPU: NVIDIA GPU with at least 24GB VRAM (e.g., RTX 3090, RTX 4090, A5000)
- RAM: 32GB system memory
- Storage: 20GB for model weights and dependencies
- CUDA: CUDA 11.8 or higher
Recommended Configuration:
- GPU: NVIDIA A100 (40GB/80GB) or H100 for optimal performance
- RAM: 64GB or more for processing multiple audio files
- Storage: SSD with 50GB+ free space
- CUDA: CUDA 12.0 or higher
For production deployments, cloud-based GPU instances (AWS, Azure, Google Cloud) with A100 or similar GPUs are recommended to ensure consistent performance and scalability.
Comparison with Competing ASR Models
VibeVoice-ASR vs. OpenAI Whisper
OpenAI's Whisper Large V3 has been a dominant player in the ASR space, but VibeVoice-ASR offers several advantages:
VibeVoice-ASR Advantages:
- Native support for 60-minute single-pass processing
- Integrated speaker diarization without additional models
- Built-in timestamping with high precision
- Custom hotword support for domain-specific accuracy
- Optimized for long-form content
Whisper Advantages:
- Support for 100+ languages
- Proven robustness in noisy environments
- Multiple model sizes for different use cases
- Extensive community support and integrations
Use Case Recommendations:
- Choose VibeVoice-ASR for: Long meetings, interviews, podcasts, and content requiring speaker identification
- Choose Whisper for: Multilingual content, noisy environments, and edge device deployment
VibeVoice-ASR vs. Deepgram Nova-2
Deepgram Nova-2 is a commercial ASR solution known for its speed and accuracy:
VibeVoice-ASR Advantages:
- Open-source and free to use
- Integrated speaker diarization
- Better handling of very long audio files (60 minutes)
- Custom hotword support included
Deepgram Nova-2 Advantages:
- Lower latency for real-time applications
- Managed API service with high availability
- Domain-specific models (medical, finance, etc.)
- Enterprise support and SLAs
Cost Comparison:
- VibeVoice-ASR: Free (self-hosted infrastructure costs only)
- Deepgram Nova-2: Pay-per-use pricing starting at $0.0043/minute
VibeVoice-ASR vs. Google Chirp
Google's Chirp model is part of their Cloud Speech AI offering:
VibeVoice-ASR Advantages:
- Open-source with full control over deployment
- No usage limits or quotas
- Better for privacy-sensitive applications
- Integrated speaker diarization
Google Chirp Advantages:
- Extensive language support (100+ languages)
- Managed service with automatic scaling
- Integration with Google Cloud ecosystem
- Continuous model updates
Getting Started with VibeVoice-ASR
Installation
VibeVoice-ASR can be installed and deployed using the official GitHub repository:
# Clone the repository
git clone https://github.com/microsoft/VibeVoice.git
cd VibeVoice
# Install dependencies
pip install -r requirements.txt
# Download the model from Hugging Face
# The model will be automatically downloaded on first useBasic Usage Example
from vibevoice import VibeVoiceASR
# Initialize the model
model = VibeVoiceASR.from_pretrained("microsoft/VibeVoice-ASR")
# Load audio file
audio_path = "meeting_recording.wav"
# Perform transcription with speaker diarization
result = model.transcribe(
audio_path,
enable_diarization=True,
enable_timestamps=True,
hotwords=["VibeVoice", "Microsoft", "ASR"]
)
# Access structured output
for segment in result.segments:
print(f"[{segment.start:.2f}s - {segment.end:.2f}s]")
print(f"Speaker {segment.speaker}: {segment.text}")Advanced Configuration
# Configure model for optimal performance
config = {
"max_audio_length": 3600, # 60 minutes in seconds
"beam_size": 5,
"language": "en",
"enable_hotwords": True,
"diarization_threshold": 0.5
}
result = model.transcribe(audio_path, **config)Use Cases and Applications
Meeting Transcription and Analysis
VibeVoice-ASR excels at transcribing business meetings, providing:
- Accurate speaker identification for multi-participant discussions
- Precise timestamps for easy navigation and reference
- Support for technical terminology through custom hotwords
- Complete transcription of hour-long meetings in a single pass
Benefits:
- Automated meeting minutes generation
- Searchable meeting archives
- Action item extraction
- Compliance and record-keeping
Podcast and Video Content Indexing
Content creators can leverage VibeVoice-ASR for:
- Generating accurate transcripts for accessibility
- Creating searchable content databases
- Extracting key quotes and highlights
- Enabling content repurposing across platforms
Interview Documentation
Journalists, researchers, and HR professionals benefit from:
- Verbatim transcription of interviews
- Speaker identification for multi-person interviews
- Time-coded references for easy quote verification
- Support for domain-specific terminology
Legal and Medical Transcription
Professional transcription services can utilize VibeVoice-ASR for:
- Court proceedings and depositions
- Medical consultations and patient interviews
- Compliance documentation
- Confidential on-premises processing
Best Practices for Optimal Results
Audio Quality Optimization
To achieve the best transcription accuracy with VibeVoice-ASR:
Recommended Audio Specifications:
- Sample Rate: 16 kHz or higher
- Bit Depth: 16-bit or 24-bit
- Format: WAV, FLAC, or high-quality MP3
- Channels: Mono or stereo
Recording Environment:
- Minimize background noise
- Use quality microphones
- Maintain consistent speaker distance from microphone
- Avoid audio compression artifacts
Effective Hotword Usage
Maximize transcription accuracy by providing relevant hotwords:
hotwords = [
"VibeVoice-ASR",
"Microsoft Azure",
"machine learning",
"neural network",
"API endpoint"
]
result = model.transcribe(audio_path, hotwords=hotwords)Hotword Best Practices:
- Include company names, product names, and brand terms
- Add technical terminology specific to your domain
- Include proper nouns (people names, locations)
- Keep the hotword list focused (10-50 terms recommended)
- Update hotwords based on transcription results
Limitations and Considerations
While VibeVoice-ASR offers impressive capabilities, users should be aware of certain limitations:
Current Limitations
Language Support:
- Primary focus on English language transcription
- Limited multilingual capabilities compared to Whisper
- May require fine-tuning for non-English languages
Computational Requirements:
- Requires high-end GPU hardware (24GB+ VRAM)
- Not suitable for edge devices or low-resource environments
- Significant infrastructure costs for large-scale deployments
Audio Length:
- Optimized for up to 60 minutes of audio
- Longer recordings may require segmentation
- Performance may degrade with extremely long files
Recommended Use Cases
VibeVoice-ASR is best suited for:
- Enterprise meeting transcription
- Professional content creation
- Research and academic applications
- Legal and medical documentation
- Any scenario requiring speaker diarization and long-form audio processing
Conclusion
Microsoft VibeVoice-ASR represents a significant advancement in speech recognition technology, particularly for long-form audio processing. Its ability to handle 60 minutes of continuous audio with integrated speaker diarization and timestamping makes it an excellent choice for enterprise applications, content creators, and professional transcription services.
Key Takeaways:
- VibeVoice-ASR excels at long-form audio transcription with speaker identification
- The model requires substantial GPU resources but delivers high-quality results
- Custom hotword support enables domain-specific accuracy improvements
- Open-source nature provides flexibility and control over deployment
- Best suited for applications requiring structured transcription output
For organizations and developers seeking a powerful, open-source ASR solution for long-form audio, VibeVoice-ASR offers a compelling alternative to commercial services. While it requires significant computational resources, the combination of accuracy, speaker diarization, and customization capabilities makes it a valuable tool in the modern speech recognition landscape.
Resources and Links
- Official GitHub Repository: https://github.com/microsoft/VibeVoice
- Hugging Face Model: https://huggingface.co/microsoft/VibeVoice-ASR
- Interactive Demo: https://aka.ms/vibevoice-asr
- Documentation: GitHub Documentation
- Contact: [email protected]